O que é Doctor Droid?
DrDroid é um agente de SRE com IA criado para transformar como equipes de engenharia lidam com incidentes em produção. Em vez de depender apenas dos engenheiros mais experientes — ou pior, ficar preso em "combate a incêndios" durante plantões — qualquer membro da equipe pode investigar e resolver problemas rapidamente, mesmo sem conhecer todos os detalhes do sistema.
O segredo? DrDroid entende automaticamente toda a sua infraestrutura: serviços, dependências, implantações recentes, logs, métricas e até o contexto de negócios. Isso significa que novos engenheiros podem agir como especialistas desde o primeiro dia, reduzindo o tempo médio de resolução (MTTR) e evitando escalonamentos desnecessários.
Quais são as características de Doctor Droid?
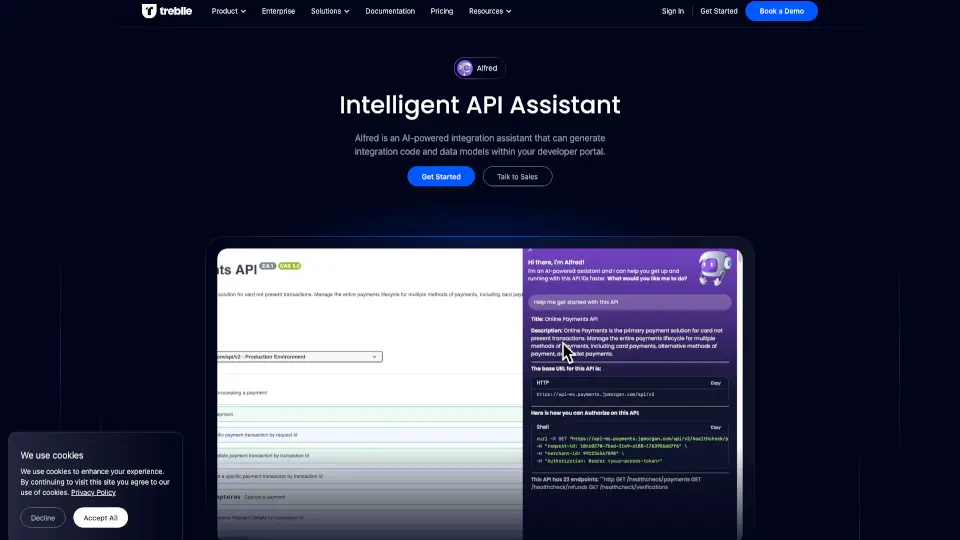
- Investigações automatizadas com IA: Qualquer engenheiro executa uma investigação no nível de um SRE sênior em minutos, não em horas.
- Verificações proativas em linguagem natural: Crie regras complexas como “verifique a saúde dos nós do Kubernetes” sem precisar escrever consultas técnicas.
- Inteligência de alertas: Agrupa alertas relacionados por causa raiz real, suprime ruído e destaca o que realmente importa.
- Transferência de conhecimento centralizada: Captura o “conhecimento tribal” da equipe e o transforma em memória acessível a todos.
- Análise de custos e segurança: Identifica recursos ociosos, instâncias superdimensionadas e oportunidades de economia em múltiplas nuvens.
- Saúde da observabilidade: Detecta alertas obsoletos, painéis incompletos e lacunas de monitoramento em novos serviços.
- Mapa contextual automático: Constrói um grafo unificado de código, infraestrutura e fluxos de negócio sem configuração manual.
- Integração com +80 ferramentas: Conecta-se a Kubernetes, Datadog, ArgoCD, AWS, GCP, Slack, PagerDuty e muito mais via servidores MCP pré-construídos.
Quais são os casos de uso de Doctor Droid?
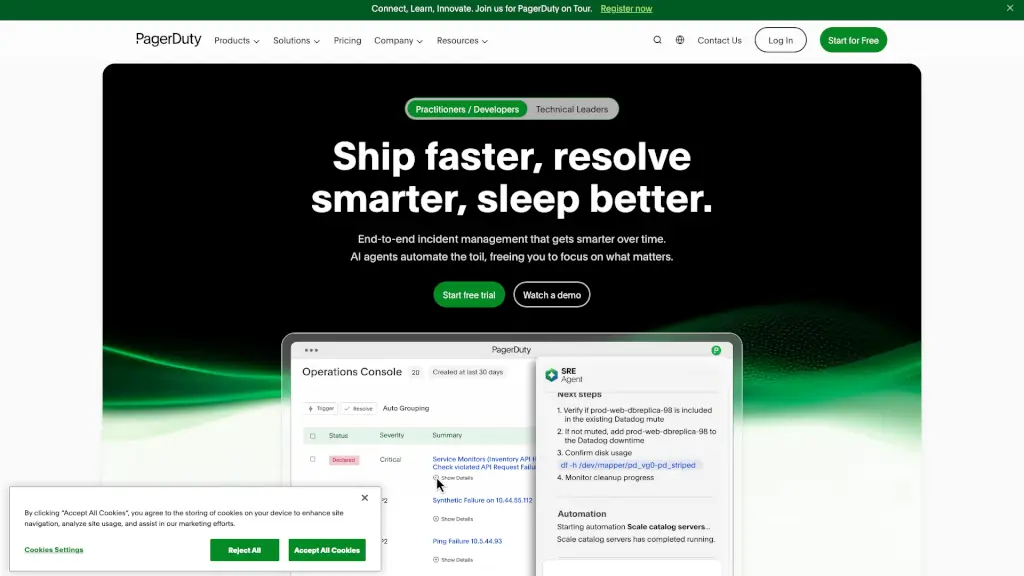
- Um engenheiro de plantão recebe um alerta às 3h da manhã e resolve o incidente diretamente pelo Slack em menos de 5 minutos.
- Uma falha silenciosa — com aumento gradual de latência em etcd, reinícios do kubelet e pods pendentes — é detectada antes que cause impacto real.
- Após a saída de um engenheiro sênior, a equipe mantém a produtividade porque todo o conhecimento está documentado no DrDroid.
- A equipe de plataforma identifica economias mensais de milhares de dólares ao redimensionar instâncias EC2 e remover volumes EBS ociosos.
- Novos contratados começam a triar incidentes com confiança em semanas, não em meses.
- Um rollout com vazamento de memória (OOMKilled) é diagnosticado automaticamente, com comparação de versões e sugestão de rollback seguro.
- Alertas duplicados ou obsoletos são removidos automaticamente, mantendo a pilha de observabilidade limpa e eficaz.
Como usar Doctor Droid?
- Conecte suas ferramentas (Kubernetes, APM, CI/CD, nuvem) em até 15 minutos.
- Peça ao DrDroid para investigar um incidente usando linguagem natural, como “por que o order-svc está em CrashLoopBackOff?”
- Crie verificações proativas com frases simples, como “verifique se há degradação silenciosa nos nós do cluster”.
- Revise os relatórios semanais de otimização de custos e saúde da observabilidade.
- Use as investigações anteriores como base para criar PlayBooks automatizados (via motor open-source PlayBooks).
- Integre com Slack ou PagerDuty para ações diretas durante incidentes.