Что такое Doctor Droid?
DrDroid — это интеллектуальный агент для SRE (Site Reliability Engineering), который помогает инженерам быстро находить и устранять сбои в продакшене без участия старших коллег или «племенных знаний». Он автоматически анализирует логи, метрики, развертывания и зависимости между сервисами, чтобы любой член команды мог провести расследование уровня эксперта — даже ночью или будучи новичком.
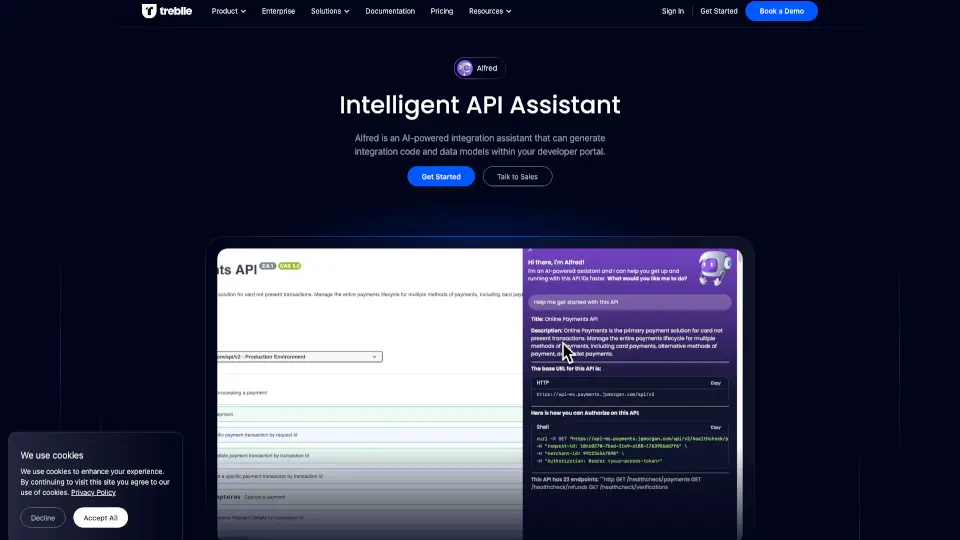
Вместо того чтобы переключаться между десятком инструментов в панике при аварии, вы просто задаёте вопрос — например: «Почему order-svc падает в CrashLoopBackOff?» — и DrDroid за 2–3 минуты находит корневую причину, используя данные из Kubernetes, Grafana, ArgoCD, Datadog и других систем. Это превращает реактивное «тушение пожаров» в проактивное построение устойчивой инфраструктуры.
Какие особенности у Doctor Droid?
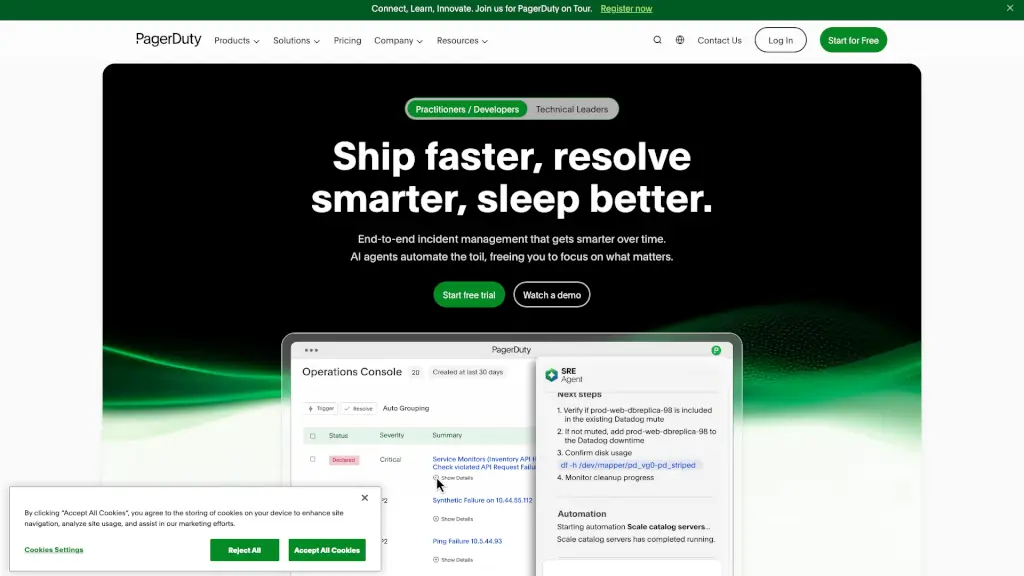
- Автоматическое расследование инцидентов: Агент сам проверяет поды, логи, развертывания и конфигурации, чтобы найти корневую причину — как лучший SRE в вашей команде.
- Проактивные проверки на естественном языке: Пишете простую фразу вроде «Проверь здоровье нод в кластере», и DrDroid запускает комплексную диагностику каждые 30 минут.
- Интеллектуальная группировка алертов: Вместо сотен шумных уведомлений вы получаете один инцидент с реальной причиной, основанной на архитектуре и недавних изменениях.
- Центр знаний без «племенных тайн»: Вся контекстная информация об инфраструктуре, сервисах и workflow сохраняется в системе — новые сотрудники становятся продуктивными за недели, а не месяцы.
- Анализ затрат и оптимизация: Автоматически находит неиспользуемые ресурсы, завышенные лимиты и возможности для экономии (например, переход на Reserved Instances).
- Поддержка 80+ интеграций: Работает с Kubernetes, AWS, GCP, Datadog, Prometheus, GitHub, PagerDuty и многими другими через преднастроенные MCP-серверы.
- Автоматическое обновление наблюдаемости: Находит «слепые зоны» — новые сервисы без мониторинга, устаревшие дашборды и дублирующие алерты.
Какие случаи использования Doctor Droid?
- Инженер получает пейджер в 3 часа ночи — просит DrDroid расследовать проблему в Slack и закрывает инцидент за 5 минут.
- Команда обнаруживает «тихую деградацию» ноды до того, как начнутся сбои: высокая задержка диска + перезапуски kubelet + pending-поды.
- Новичок в компании самостоятельно отлаживает проблему в микросервисной архитектуре из 100+ сервисов благодаря автоматически построенной карте зависимостей.
- SRE-команда ежемесячно экономит тысячи долларов, применяя рекомендации DrDroid по правильному размеру EC2, удалению неиспользуемых томов и резервированию БД.
- После деплоя новой версии сервиса DrDroid автоматически связывает OOMKilled с добавленным OpenTelemetry SDK и предлагает безопасный откат + исправленную конфигурацию.
Как использовать Doctor Droid?
- Подключите DrDroid к своим инструментам (Kubernetes, облака, APM) — это займёт менее 15 минут.
- Задавайте вопросы прямо в Slack, интерфейсе DrDroid или через CLI: «Почему упала конверсия в чекауте?» или «Проверь memory leak в payment-svc».
- Создавайте проактивные проверки на естественном языке и запускайте их по расписанию (например, каждые 30 минут).
- Используйте рекомендации по оптимизации затрат и безопасности — они обновляются еженедельно.
- Разрешите DrDroid автоматически улучшать вашу систему наблюдаемости: он найдёт устаревшие алерты и добавит мониторинг для новых сервисов.
- Для сложных сценариев добавьте свои внутренние инструменты через кастомные MCP-серверы или навыки.