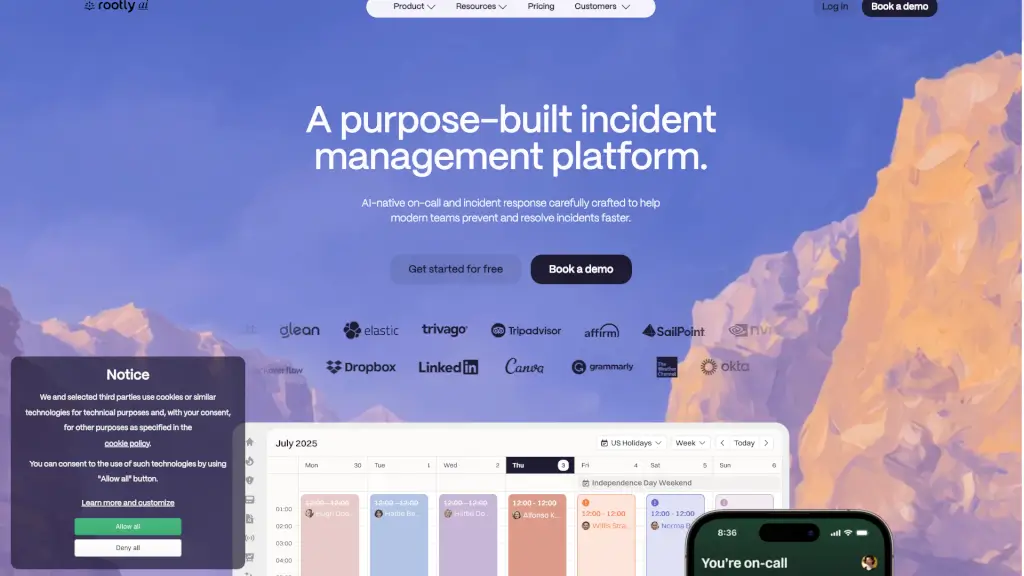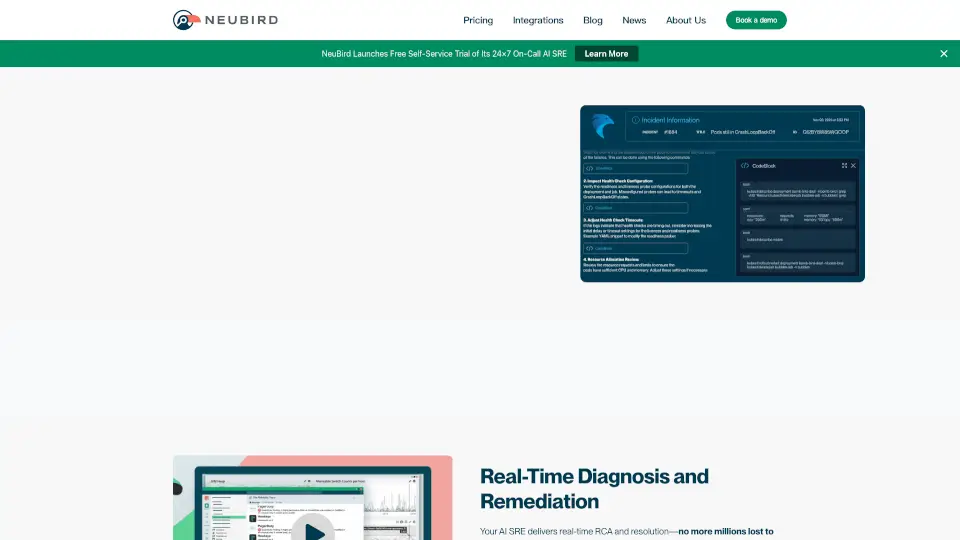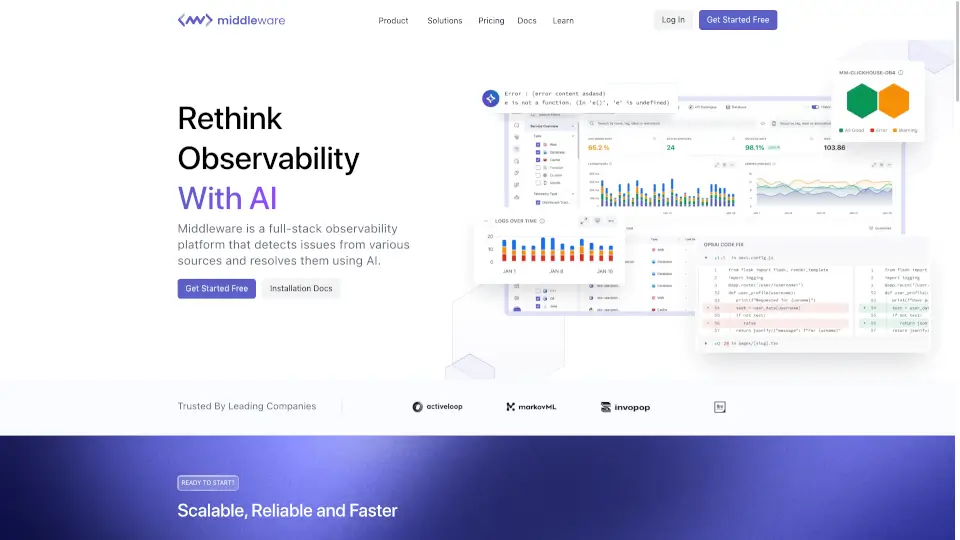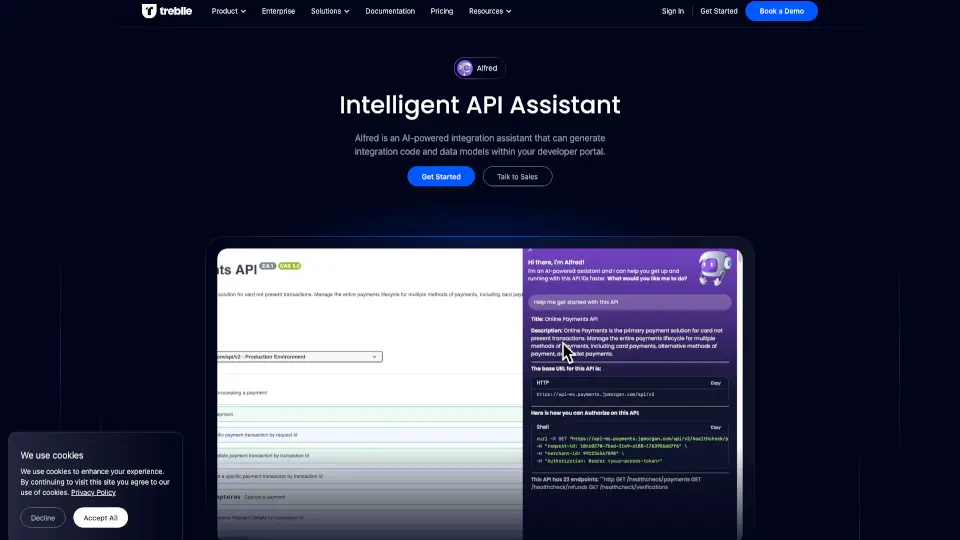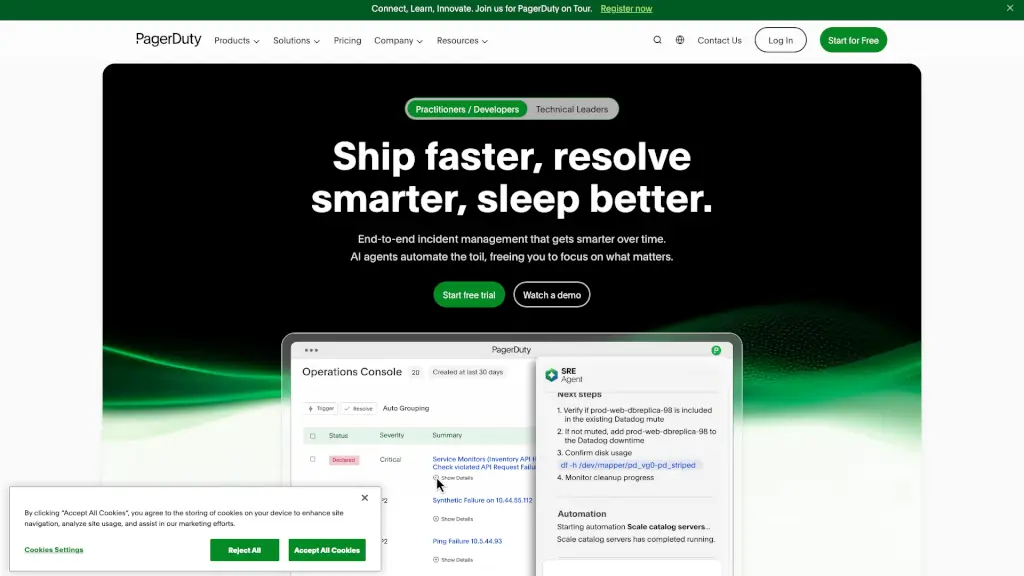
Doctor Droidとは何ですか?
DrDroid(ドクタードロイド)は、AI搭載のSREエージェントで、本番環境でのインシデント対応や根本原因分析を誰でも簡単にできるようにします。従来は経験豊富なエンジニアだけが知っていた「どこを見ればいいか」「どのログが重要か」といったトライブナレッジ(暗黙知)をAIが自動的に学習・活用し、新人エンジニアでも即戦力として対応可能に。
クラウド、Kubernetes、CI/CD、監視ツールなど80種類以上のシステムと連携し、全インフラ構成を自動でマッピング。メトリクス・ログ・トレースを横断的に分析して、単体のアラートでは見逃されがちな「静かな障害」も検出。MTTR(平均復旧時間)を大幅に短縮し、夜中のポケベルから解放される未来を実現します。
Doctor Droidの特徴は何ですか?
- AIによる自動調査: CrashLoopBackOffやパフォーマンス劣化などのインシデントを2分以内に調査・根本原因を特定
- 自然言語での監視設定: 「ノードのCPU圧力とポッド退避率をチェック」など、平易な日本語で複雑な監視ルールを定義
- アラートインテリジェンス: 関連するアラートを自動グルーピングし、ノイズを抑制して真のインシデントのみを通知
- トライブナレッジの可視化: サービス間依存関係やデプロイ履歴、所有者情報を統合し、組織の知識を永続化
- コスト最適化レポート: 未使用リソースや過剰プロビジョニングを自動検出し、月額数千ドル規模の節約を提案
- オブザーバビリティ健全性チェック: ステイルアラートの削除や新サービスへの監視カバレッジ自動追加で、監視体制を常に最新に維持
Doctor Droidの使用例は何ですか?
- 夜中にPagerDutyでアラートが鳴ったが、SlackでDrDroidに質問して5分で根本原因を特定・対応完了
- 新入社員が初めてのオンコール当番で、先輩の助けなしに本番インシデントを自力で解決
- マイクロサービス間の複雑な依存関係で発生した遅延を、トレースとログを横断して迅速に切り分け
- Kubernetesクラスタで発生中の「静かな劣化」(ディスクI/O遅延+kubelet再起動増加)を事前に検出して障害を未然防止
- 月次コストレビューで、未使用EBSボリュームや過剰なEC2インスタンスを自動検出し4,000ドル以上を節約
- 新規サービス「auth-service」のデプロイ後、自動で監視ルールとダッシュボードを生成しカバレッジギャップを解消
Doctor Droidの使い方は?
- 15分でツール連携: AWS、GCP、Kubernetes、Datadog、GitHub、ArgoCDなど既存ツールを接続
- 自然言語でチェック作成: 「注文サービスのメモリリークを監視」など、日本語で監視ルールを記述
- Slack/PagerDutyから直接問い合わせ: 「order-svcがCrashLoopしてる原因は?」とチャット形式で質問
- 調査結果を確認・実行: AIが提示したロールバック提案や設定変更をワンクリックで適用可能
- 週次レポートで改善継続: コスト最適化や監視健全性の自動レポートをチームで共有
- PlayBooksでカスタム診断を拡張: オープンソースの診断エンジンで社内固有のワークフローを自動化