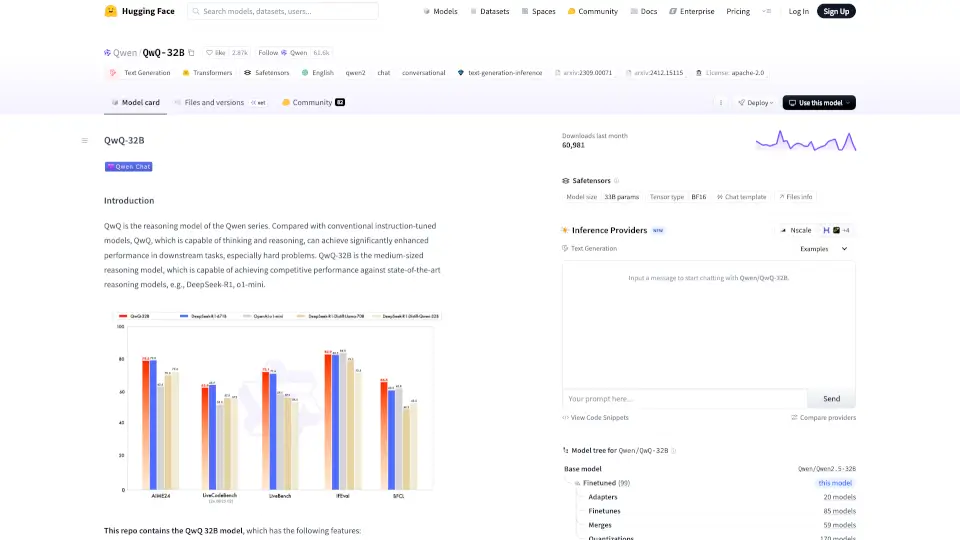
Qu'est-ce que QwQ-32B ?
Découvrez Qwen/QwQ-32B, un modèle de langage révolutionnaire qui améliore la génération de texte grâce à sa capacité de raisonnement. Conçu pour exceller dans des tâches complexes, il surpasse les modèles traditionnels en offrant des performances de pointe.
Quelles sont les caractéristiques de QwQ-32B ?
- Type: Modèles de langage causaux
- Architecture: Transformers avec RoPE, SwiGLU, RMSNorm
- Nombre de paramètres: 32,5 milliards
- Longueur de contexte: 131 072 tokens
- Optimisation: Entraînement supervisé et apprentissage par renforcement
Quels sont les cas d'utilisation de QwQ-32B ?
- Génération de texte conversationnel
- Résolution de problèmes mathématiques
- Réponses à des questions à choix multiples
Comment utiliser QwQ-32B ?
Pour utiliser Qwen/QwQ-32B, chargez le modèle et le tokenizer avec le code suivant :
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Combien de r's y a-t-il dans le mot \"fraise\" ?"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)