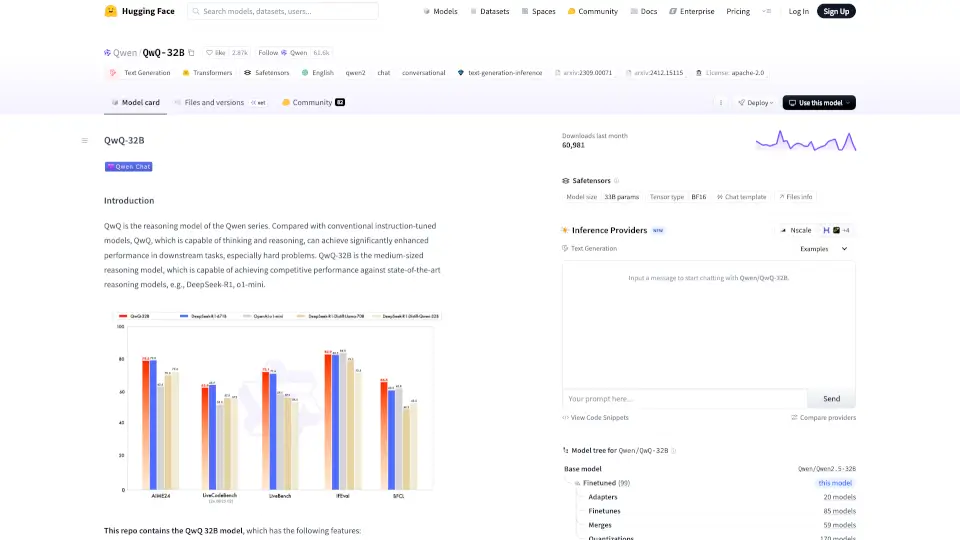
什么是QwQ-32B?
Qwen/QwQ-32B 是一款先进的推理模型,旨在通过开源和开放科学推动人工智能的发展。与传统的指令调优模型相比,QwQ 能够进行更深层次的思考和推理,在下游任务中表现出色,尤其是在解决复杂问题时。
QwQ-32B的核心功能有哪些?
- 类型: 因果语言模型
- 参数数量: 32.5B
- 层数: 64
- 注意力头数: Q 40,KV 8
- 上下文长度: 131,072 个标记
- 训练阶段: 预训练与后训练(监督微调和强化学习)
QwQ-32B的使用案例有哪些?
- 文本生成: 适用于各种文本生成任务。
- 对话系统: 可用于构建智能对话机器人。
- 复杂问题解决: 在数学和逻辑推理方面表现优异。
如何使用QwQ-32B?
使用以下代码加载模型和生成内容:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)