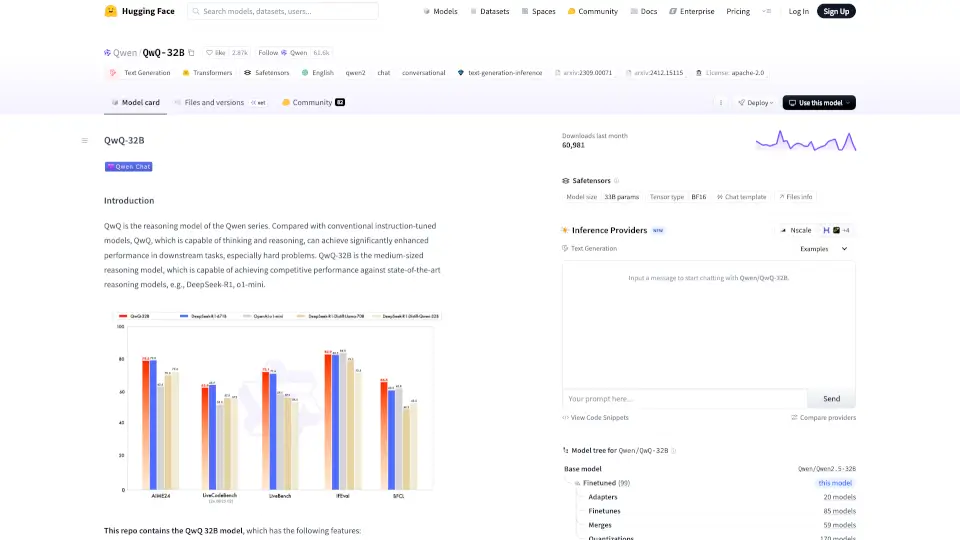
What is QwQ-32B?
Introducing Qwen/QwQ-32B, a cutting-edge reasoning model designed to enhance your AI experience. This model stands out with its ability to think and reason, making it a powerful tool for tackling complex tasks.
What are the features of QwQ-32B?
- Type: Causal Language Models
- Architecture: Transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Parameters: 32.5 billion total, with 31 billion non-embedding
- Layers: 64
- Attention Heads: 40 for Q and 8 for KV
- Context Length: Full 131,072 tokens
What are the use cases of QwQ-32B?
- Text Generation: Create engaging and coherent text for various applications.
- Conversational AI: Power chatbots and virtual assistants with advanced reasoning capabilities.
- Complex Problem Solving: Tackle challenging questions and tasks with ease.
How to use QwQ-32B?
To get started, load the model and tokenizer using the following code snippet:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)