什么是StableBeluga2?
Stable Beluga 2 是 Stability AI 推出的一款强大开源语言模型,基于 Llama2 70B 架构,并在高质量的 Orca 风格数据集上进行了精细微调。它专为遵循指令、安全可靠地完成各类文本生成任务而设计,适合开发者、研究人员和企业用户探索先进 AI 能力。
作为 Stability AI “Beluga” 系列的重要成员,Stable Beluga 2 在保持高性能的同时,强调负责任的 AI 使用。虽然仅限非商业用途,但它为社区提供了一个透明、可复现的平台,推动开放科学与开源 AI 的发展。
StableBeluga2的核心功能有哪些?
- 基于 Llama2 70B 微调:继承 Llama2 强大的语言理解能力,并通过 Orca 数据进一步优化指令遵循表现
- Orca 风格训练数据:使用模仿 GPT-4 复杂推理轨迹的数据进行监督微调,提升逻辑性和回答质量
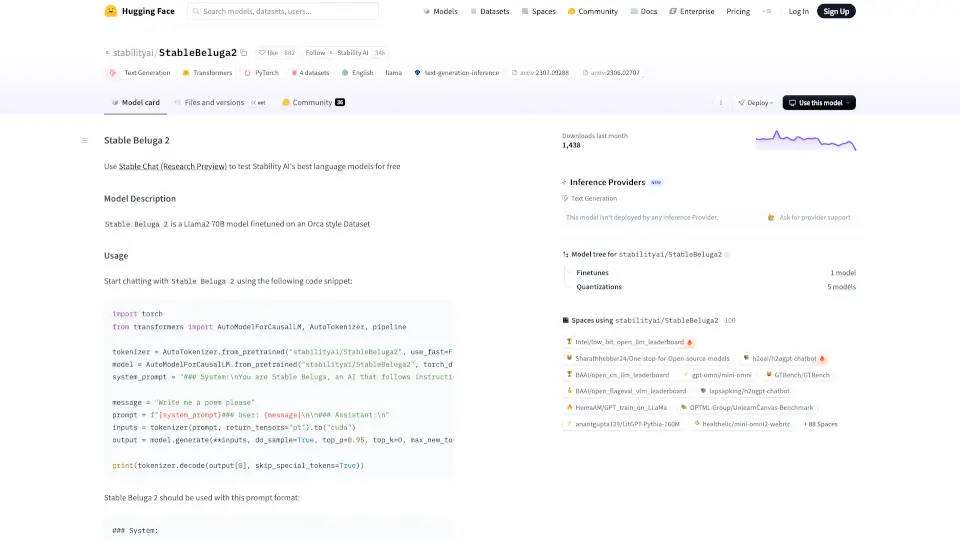
- 明确的提示格式要求:采用
### System/### User/### Assistant三段式结构,确保输出稳定可控 - Hugging Face 原生支持:可通过 Transformers、vLLM、SGLang 等主流库轻松部署和调用
- 多种量化版本可用:支持 llama.cpp、Ollama、LM Studio 等本地运行环境,降低硬件门槛
- 非商业开源许可:在 STABLE BELUGA NON-COMMERCIAL COMMUNITY LICENSE 下免费供研究和学习使用
StableBeluga2的使用案例有哪些?
- 开发者快速搭建本地聊天机器人原型
- 研究人员测试指令微调模型在复杂任务中的表现
- 教育场景中用于诗歌、故事等创意文本生成
- 企业内部知识库问答系统的实验性探索(需注意许可限制)
- 对比不同开源大模型的推理能力与安全性
- 在 Colab 或 Kaggle 上进行零成本 AI 实验
如何使用StableBeluga2?
- 安装 transformers 库后,使用
pipeline("text-generation", model="stabilityai/StableBeluga2")快速调用 - 加载模型时建议设置
torch_dtype=torch.float16和device_map="auto"以节省显存 - 必须使用指定提示模板:以
### System:\n...开头,接着### User: [你的问题],最后以### Assistant:\n结尾 - 若需高性能推理,推荐使用 vLLM 或 SGLang 启动 OpenAI 兼容 API 服务
- 本地运行前请确认 GPU 显存充足(70B 模型通常需 2×24GB 或以上)
- 商业项目请勿直接使用——该模型仅限非商业用途
StableBeluga2联系邮箱:
StableBeluga2常见问题:
Q: Stable Beluga 2 可以用于商业项目吗?
A: 不可以。该模型采用 STABLE BELUGA NON-COMMERCIAL COMMUNITY LICENSE,仅限非商业用途。商业应用需联系 Stability AI 获取授权。
Q: 如何正确构造输入提示(prompt)?
A: 必须使用三段式格式:
`### System:\n[系统指令]\n\n### User:\n[用户问题]\n\n#