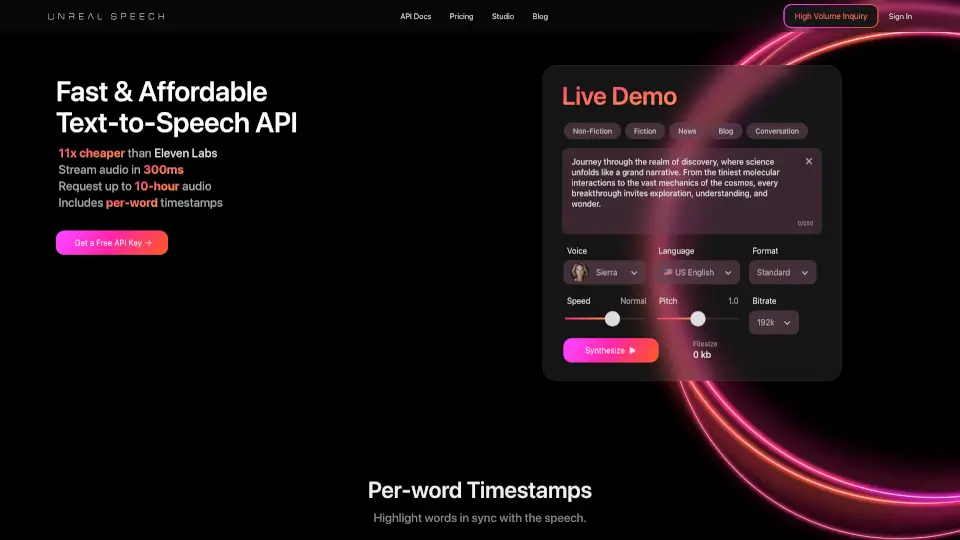
Что такое Unreal Speech?
Unreal Speech — это самый доступный API для преобразования текста в речь, который помогает сэкономить до 91% по сравнению с конкурентами вроде ElevenLabs. Сервис идеально подходит как для стартапов, так и для крупных компаний: он предлагает высокое качество звука, сверхнизкую задержку (всего 300 мс) и поддержку длинных аудиозаписей — до 10 часов за один запрос.
Благодаря продуманной ценовой модели вы платите только за использованные символы, а первые 250 000 символов — бесплатно каждый месяц. Это делает Unreal Speech отличным выбором для разработчиков, создателей контента и edtech-платформ, которым нужно масштабируемое и экономичное решение для озвучки текста без ущерба для качества.
Какие особенности у Unreal Speech?
- Сверхнизкая цена: В 11 раз дешевле ElevenLabs при сопоставимом или лучшем качестве
- Мгновенная потоковая передача: Аудио начинает воспроизводиться уже через 300 миллисекунд
- Длинные аудиофайлы: Поддержка генерации записей продолжительностью до 10 часов
- Переходные метки по словам: Точная синхронизация слов с речью для подсветки в реальном времени
- 48 голосов на 8 языках: Включая английский (США и Великобритания), китайский, хинди, испанский, португальский, японский, французский и итальянский
- Гибкие форматы и настройки: Выбор битрейта (до 192k), скорости, тональности и кодека (MP3 или PCM µ-law)
Какие случаи использования Unreal Speech?
- Озвучка подкастов и аудиокниг для платформ цифрового контента
- Создание интерактивных обучающих приложений с синхронной подсветкой текста
- Автоматизация колл-центров и голосовых уведомлений для бизнеса
- Интеграция в мобильные приложения для чтения новостей вслух
- Генерация персонализированных аудиосообщений в CRM и маркетинговых системах
- Поддержка пользователей с нарушениями зрения через screen reader нового поколения
Как использовать Unreal Speech?
- Зарегистрируйтесь и получите бесплатный API-ключ на сайте Unreal Speech
- Выберите подходящий эндпоинт:
/streamдля коротких фраз (до 1000 символов),/speechдля средних текстов (до 3000 символов) или/synthesisTasksдля длинных аудиофайлов (до 500 000 символов) - Укажите
VoiceId, язык, битрейт и другие параметры в JSON-запросе - Для получения временных меток используйте параметр
TimestampType: "word"или подключайтесь через WebSocket к/streamWithTimestamps - Обрабатывайте ответ: скачивайте аудио напрямую или получайте ссылки на MP3 и JSON с метками
- Следите за использованием символов — бесплатный лимит обновляется ежемесячно