什么是Unreal Speech?
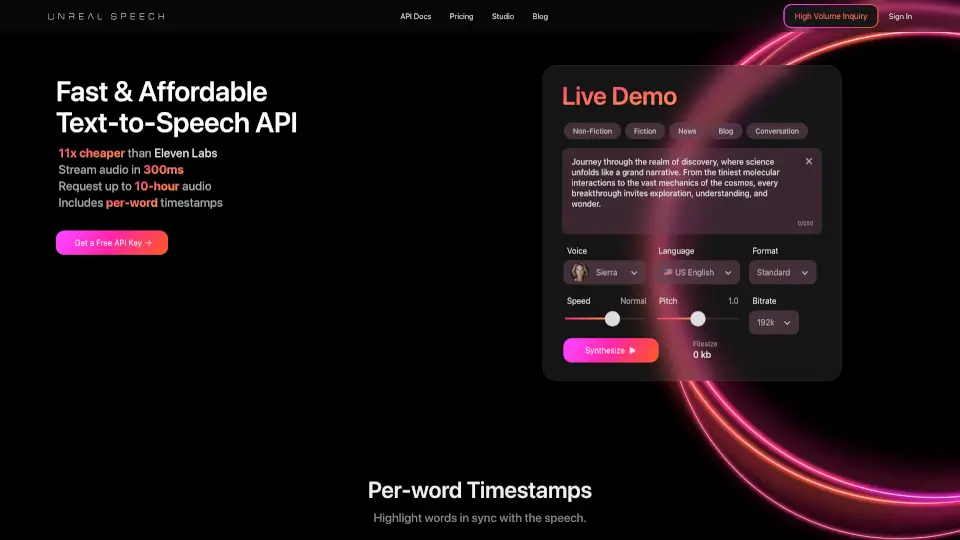
Unreal Speech 是一款超低成本、高性能的文本转语音(TTS)API,专为开发者和企业打造。相比 ElevenLabs 等主流服务,它便宜高达 11 倍,同时保持出色的语音质量和极低延迟——音频流可在 300 毫秒内开始播放。无论你是构建实时对话应用、有声读物平台,还是需要批量生成数小时音频内容,Unreal Speech 都能以极具竞争力的价格提供生产级解决方案。
它不仅支持长达 10 小时的单次音频生成,还提供 48 种自然逼真的语音,覆盖 8 种语言(包括中文普通话、英语、西班牙语、日语等),并附带精准的逐词时间戳功能,让字幕同步、高亮朗读等交互体验轻松实现。
Unreal Speech的核心功能有哪些?
- 超低价格:比 ElevenLabs 便宜 11 倍,企业级用量每百万字符仅需 $8
- 极速响应:/stream 接口 300ms 内返回音频,适合实时应用
- 长音频支持:单次请求可生成长达 10 小时的高质量音频
- 多语言多音色:48 种语音,涵盖中、英、西、日、法、意、葡、印地语等 8 种语言
- 逐词时间戳:精确到单词级别的起止时间,便于同步高亮或字幕
- 免费额度大:新用户赠送 25 万字符免费额度,无信用卡要求
- 商业可用:付费计划生成的音频可直接用于商业项目,无需署名
Unreal Speech的使用案例有哪些?
- 在线教育平台为课程内容自动生成带字幕的语音讲解
- 有声书或播客应用批量合成数小时长篇内容
- 客服机器人或语音助手实现实时、自然的语音回复
- 新闻或博客网站为文章提供“听新闻”功能
- 语言学习 App 实现句子跟读与发音对比
- 游戏或元宇宙场景中动态生成角色对话
- 无障碍工具为视障用户提供网页内容朗读
如何使用Unreal Speech?
- 注册账号并获取 免费 API 密钥(无需绑定信用卡)
- 根据需求选择合适接口:短文本用
/stream(≤1000 字符),中等长度用/speech(≤3000 字符),长文本用异步/synthesisTasks(最高 50 万字符) - 在请求中指定
VoiceId(如 "Sierra"、"Hannah" 或中文语音)、语言、比特率等参数 - 若需时间戳,在
/speech或/synthesisTasks中设置TimestampType为 "word" 或 "sentence" - 对于实时字幕高亮,使用 WebSocket 接口
/streamWithTimestamps - 查看 API 文档获取完整参数列表和代码示例(支持 Python、Node.js、React Native、cURL 等)