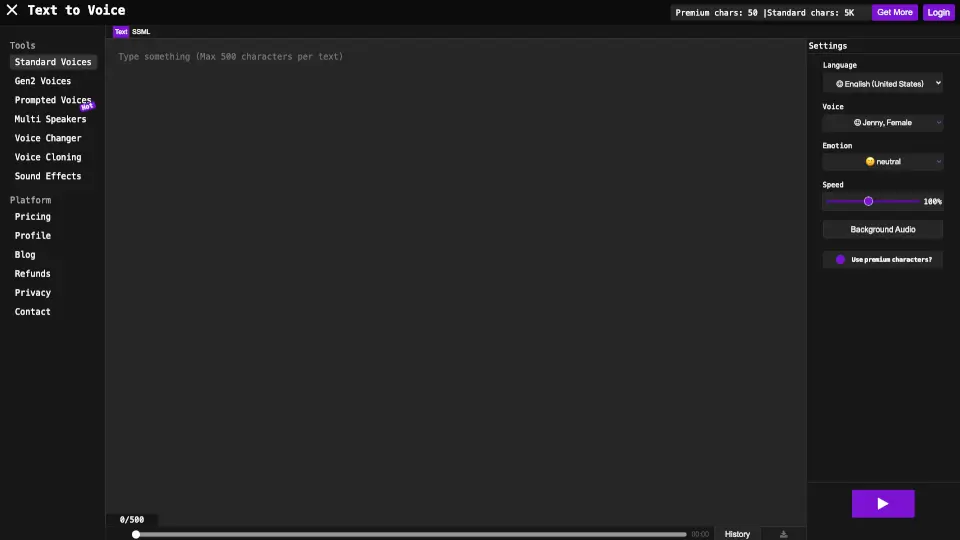
什麼是ChatTTS?
ChatTTS 是一款專為對話場景設計的語音生成模型,可用於大型語言模型助理的對話任務、互動音訊與影片介紹等應用。支援中文與英文,透過約十萬小時的雙語資料訓練,能產出高品質且自然的合成語音。團隊也計畫開源一個以四萬小時資料訓練的基礎模型,幫助學術與開發社群進一步研究與開發。
ChatTTS的特色是什麼?
- 多語言支援:一次支援中文與英文,讓不同語言的用戶都能輕鬆使用。
- 大量資料訓練:使用約十萬小時的中英文語音資料訓練,確保語音自然、高品質。
- 對話任務相容:專門為大型語言模型的對話任務最佳化,能生成流暢自然的回覆。
- 開源計畫:團隊將開源一個以四萬小時資料訓練的基礎模型,鼓勵社群研究與創新。
- 控制與安全性:持續改善模型的可控性、加入浮水印,並與大型語言模型整合,確保安全可靠。
- 易於使用:只要輸入文字,就能自動產出對應的語音檔案,操作簡單直覺。
ChatTTS的使用案例有哪些?
- 用於大型語言模型助理的對話回覆生成
- 製作影音介紹或教學內容的旁白語音
- 為聊天機器人、客服系統提供自然語音輸出
- 教育訓練內容的語音合成
- 任何需要文字轉語音的應用或服務
如何使用ChatTTS?
- 從 GitHub 下載程式碼:
git clone https://github.com/2noise/ChatTTS - 安裝必要套件:
pip install torch ChatTTS - 匯入所需函式庫(torch、ChatTTS、IPython.display.Audio)
- 初始化 ChatTTS 模型並載入預訓練權重
- 準備要轉換的文字,例如
texts = ["你好,歡迎使用 ChatTTS!"] - 呼叫
chat.infer(texts, use_decoder=True)生成語音 - 使用
Audio(wavs[0], rate=24000, autoplay=True)播放音訊